
Bagaimana AI dapat mempelajari bahasa manusia untuk mempermudah hidup kita

Di balik kemudahan teknologi digital yang kita gunakan sehari-sehari seperti mesin penerjemahan, e-mail, search engine, dan chatbot (misalnya Siri, Alexa, Google Assistant) ada kompleksitas mesin yang mampu menampilkan data, kata, gambar, dan video dalam hitungan milidetik. Di balik teknologi tersebut, kata, kalimat, dan bahasa menjadi kuncinya. Bagaimana mesin mempelajari linguistik manusia?
Jawabannya adalah artificial intelligence (AI). Teknologi AI merupakan salah satu teknologi masa depan yang dapat mengubah industri bersamaan dengan teknologi “mobile”, “Internet of Things”, dan “cloud”.
Seperti namanya, teknologi AI atau kecerdasan buatan ini mampu membuat komputer dapat bertindak atau mengambil keputusan seperti manusia. Salah satu bagian dari AI adalah bidang natural language processing (NLP) atau pemrosesan bahasa alami. Teknologi NLP ini yang memungkinkan komputer dapat memahami dan mensintesis teks yang ditulis dalam bahasa manusia.
Meski istilah NLP belum banyak dikenal masyarakat luas, sebenarnya masyarakat pengguna internet sudah sangat sering menggunakan teknologi NLP ini. Bukan hanya aplikasi chatbotyang memang merupakan salah satu target utama dari teknologi NLP, teknologi NLP terdapat juga dalam berbagai aplikasi yang digunakan sehari-hari.
Salah satu yang sering digunakan adalah search engine, seperti Google, Bing atau Yahoo. Jika kita ingin mencari informasi tertentu, kita cukup menuliskan kata kunci di search engine dan dalam hitungan milidetik, search engine akan menampilkan artikel-artikel yang relevan.
Teknologi NLP lainnya yang sering digunakan adalah mesin penerjemahan otomatis (machine translation), seperti Google translate. Fitur ini sering digunakan baik pada saat membaca atau memahami sebuah teks, atau bahkan pada saat menulis teks dalam bahasa tertentu. Selain chatbot, search engine dan machine translation, teknologi NLP juga sering digunakan dalam penyaring email/short message service(SMS) spam, pengoreksi teks otomatis, pemeriksa plagiarism, dan perekomendasi buku (contohnya pada Amazon).
Mesin penjawab otomatis dan penelisik sentimen
Saat ini, di Indonesia, semakin banyak industri yang memahami manfaat dari penggunaan teknologi NLP ini. Dua jenis teknologi NLP yang banyak digunakan industri di Indonesia adalah chatbot dan media monitoring.
Chatbot adalah teknologi NLP yang mampu melayani percakapan dengan pengguna secara otomatis. Sistem ini berusaha memahami masukan dari pengguna baik berupa teks maupun suara, dan kemudian memberikan respons sesuai dengan kalimat masukan pengguna. Banyak industri yang mulai menggunakan chatbot untuk berbagai fungsi sederhana, seperti memberikan informasi terkait perusahaan atau pemesanan layanan perusahaan tersebut.
Media monitoring analisis sentimen adalah aplikasi yang menggunakan teknologi NLP untuk membantu mengambil informasi khusus dari berbagai pendapat yang tersebar di media sosial. Untuk menjadi yang terdepan pada sebuah bisnis, perusahaan memerlukan feedbackdari pelanggannya. Saat media sosial belum berkembang, feedback ini diperoleh melalui survei yang diisi pelanggan.
Namun dengan berkembangnya penggunaan media sosial, informasi berupa pendapat pelanggan ini dapat diperoleh melalui media sosial. Kelebihan penggunaan media sosial dibandingkan survei adalah ketepatan pendapat yang bisa berubah dalam rentang waktu tertentu, kesimpulan dapat diperoleh lebih cepat, dan biaya yang lebih murah.
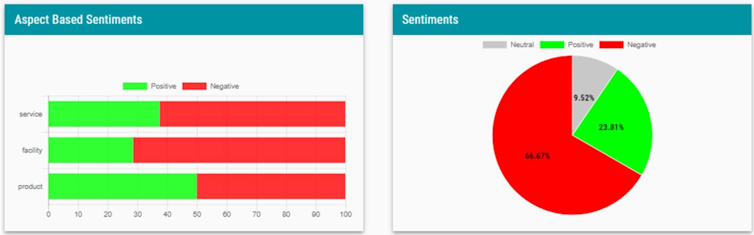
Salah satu teknologi NLP yang banyak digunakan pada aplikasi media monitoring adalah klasifikasi sentimen, teknologi untuk kategorisasi sebuah pendapat pelanggan menjadi positif atau negatif secara otomatis. Dengan klasifikasi sentimen, kita dapat mengetahui jumlah pendapat positif atau negatif terhadap sebuah produk atau layanan perusahaan secara otomatis. Gambar di bawah ini adalah contoh hasil dari klasifikasi sentimen.
Bagaimana mereka bekerja?
Pada dasarnya, strategi teknik yang sering digunakan dalam membangun teknologi NLP ini dapat dibagi menjadi dua teknik pemrosesan NLP, yaitu (1) strategi berbasis aturan yang secara manual dituliskan oleh manusia (rule based technique) atau (2) strategi berbasis aturan yang secara otomatis diperoleh dari data (statistical based technique atau machine learning based technique).
Teknik pertama digunakan jika aturan-aturan tersebut mudah dituliskan. Dalam aplikasi penyaring SMS spam, misalnya, teknik pertama diimplementasikan oleh teknisi data dengan cara menuliskan kata-kata filter yang digolongkan sebagai spam. Contoh kata penanda spam: (1) selamat Anda mendapatkan, (2) butuh pinjaman?, (3) mari berlangganan dengan… dan lainnya. Dalam konteks ini dibuat aturan bahwa jika sebuah pesan pendek mengandung lebih dari 5 kata penanda spam, maka pesan tersebut dapat dinyatakan sebagai informasi sampah.
Kelemahan dari teknik pertama ini adalah tidak akurat untuk menangani masalah yang kompleks, misalnya pola struktur kalimat yang rumit atau terdapat unknown word (kata yang tidak terdapat pada daftar kata). Hal ini yang mendorong berkembangnya teknik kedua, machine learning based technique. Dalam teknik ini, berbagai aturan (termasuk daftar kata penting) diperoleh secara otomatis melalui data.
Langkah pertama bagi para saintis untuk menggunakan teknik berbasis machine learningadalah membuat data latih. Data latih yang berkualitas merupakan salah satu kunci keberhasilan sebuah aplikasi NLP. Berikut adalah contoh data latih untuk klasifikasi spam:
“Ini mama, kartu telpon mama hilang, jadi pakai nomor ini. Tolong kirim pulsa ke nomor ini” → ditandai sebagai “SMS spam”.
“Kak, bisa kirim pulsa ke mama, ini udah mau habis, Mama perlu telpon kakak” → ditandai sebagai “SMS bukan spam”.
Setelah data latih terbangun, selanjutnya saintis menggunakan algoritme machine learninguntuk mengambil daftar kata penting dan aturan lainnya dari data latih tersebut secara otomatis.
Berbagai algoritme machine learning tradisional dapat digunakan seperti decision tree, SVM, dan XGBoost. Algoritme tersebut telah dikembangkan para ahli statistik dan ilmu komputer. Selain itu juga digunakan algoritme deep learning, yakni pengembangan dari algoritme neural network. Algoritme deep learning ini telah dibuktikan oleh banyak penelitian memiliki kinerja yang lebih baik daripada menggunakan algoritme machine learning tradisional.
Dalam teknik yang berbasis machine learning, data latih yang berkualitas (data dalam bentuk kata/kalimat) memiliki peran penting dalam membangun model yang akurat. Untuk pendekatan unsupervised learning (data latih tanpa label), data latih dapat dengan mudah dikumpulkan karena tidak memerlukan pelabelan khusus. Maksudnya, sistem atau peneliti belum sempat melabelkan apakah satu kata/kalimat tersebut spam atau tidak, misalnya dalam kasus SMS spam.
Namun untuk pendekatan supervised learning (data latih dengan label) seperti contoh klasifikasi SMS spam, penyiapan data latih yang berkualitas memerlukan upaya khusus. Ketersediaan data latih ini menjadi masalah tersendiri di Indonesia.
Saat ini, para peneliti Indonesia di bidang ilmu komputer mengumpulkan data latih masing-masing. Belum terdapat data latih untuk NLP bahasa Indonesia dengan kuantitas yang besar dan kualitas yang baik. Oleh karena itu, pada tahun 2016, dibentuk Indonesian Association for Computational Linguistics (INACL) atau disebut juga Masyarakat Linguistik Komputasi Indonesia (MALKIN), yang salah satu tujuannya adalah untuk membangun data bahasa Indonesia yang dapat mendorong kemajuan penelitian NLP Indonesia.
Jika berbagai data latih berbahasa Indonesia ini sudah mencukupi, penelitian NLP Indonesia akan maju, mendorong berbagai produk NLP bahasa Indonesia sehingga urusan hidup kita akan makin mudah dilayani oleh mesin-mesin kecerdasan buatan.
Ditulis oleh Dr. Eng. Ayu Purwarianti, ST., MT. . Muhammad Gaffar berkontribusi dalam penulisan artikel ini.